
JavaScript: Correctly Converting a Byte Array to a UTF-8 String
Posted By arwyn on February 27th, 2017
![]() As you may know, the release of Airfoil for Mac 5.5 added support for streaming audio from your Mac to Google Chromecast devices. Despite the fact that Chromecast and AirPlay receivers perform very similar functions, their internal workings are very different, and making it all work together was no small feat. Streaming audio to the Chromecast actually required us to write our own custom receiver application to run on that device itself.
As you may know, the release of Airfoil for Mac 5.5 added support for streaming audio from your Mac to Google Chromecast devices. Despite the fact that Chromecast and AirPlay receivers perform very similar functions, their internal workings are very different, and making it all work together was no small feat. Streaming audio to the Chromecast actually required us to write our own custom receiver application to run on that device itself.
Chromecast applications are written in JavaScript, and while we’ve covered a lot of ground over the years, creating a network audio player in JavaScript was definitely a new challenge. While working on this, we encountered one particularly interesting problem which didn’t seem to have a ready-made solution. After much fruitless web searching, we ultimately solved this problem ourselves, and feel that solution is worth sharing with the world at large. Non-programmer users may wish to stop reading here (go check out Airfoil for Mac if you haven’t seen it yet!), but JavaScript coders, this is for you.
A JavaScript Problem
This issue we ran into was accurately rendering metadata strings — the information on what artist and song is currently playing. Airfoil converts these strings to a stream of bytes and sends them across the network to the Chromecast receiver, which converts them back to a string for display. This sounds simple enough, but there’s a catch: Many metadata strings require special handling.
An easy example of this is accented characters, as seen in band names ranging from Queensrÿche to Sigur Rós. When converting this text to a stream of bytes, the special characters need to be encoded with something like UTF-8. When converting from a stream of bytes back to a string, the UTF-8 must be decoded back the right special characters. This is a very old, very solved problem, but it is still surprisingly easy to screw it up.
Searching for “JavaScript convert bytes to string” will bring you to numerous code samples and Stack Overflow questions. Nearly all of these answers are wrong, or at least incomplete when it comes to correctly handling UTF-8 strings. The code samples generally look like this:
function stringFromArray(data)
{
var count = data.length;
var str = "";
for(var index = 0; index < count; index += 1)
str += String.fromCharCode(data[index]);
return str;
}While this works fine for simple ASCII strings, it fails to correctly decode strings that contain special characters such as accented characters. The problem is that special characters get encoded into multi-byte sequences, but the simple loop calling fromCharCode() will treat every byte as if it were a single character. Special characters go in, and mangled sequences of ASCII come out.
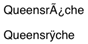
Top: Mangled; Bottom: Correct
Our JavaScript Solution
Modern string handling means dealing with UTF-8 and correctly handling special characters, so this is a common problem that should have lots of proper solutions. Unfortunately, further searching for something like “JavaScript convert UTF-8 encoded bytes to string” currently provides no additional help, instead resulting in the same wrong results as the previous query.
Hopefully, we can change that. Here’s the solution for converting bytes to a string that we worked out, which correctly handles UTF-8 encoded special characters:
function stringFromUTF8Array(data)
{
const extraByteMap = [ 1, 1, 1, 1, 2, 2, 3, 0 ];
var count = data.length;
var str = "";
for (var index = 0;index < count;)
{
var ch = data[index++];
if (ch & 0x80)
{
var extra = extraByteMap[(ch >> 3) & 0x07];
if (!(ch & 0x40) || !extra || ((index + extra) > count))
return null;
ch = ch & (0x3F >> extra);
for (;extra > 0;extra -= 1)
{
var chx = data[index++];
if ((chx & 0xC0) != 0x80)
return null;
ch = (ch << 6) | (chx & 0x3F);
}
}
str += String.fromCharCode(ch);
}
return str;
}As you can see, our version is longer than the commonly found, and incorrect examples. That additional code provides two big improvements. First, it will translate multi-byte UTF-8 sequences correctly, thereby preserving any special characters. As well, it will pick up on invalid UTF-8 sequences, so data corruption can be detected.
Hopefully, this solution will prove useful to future JavaScript coders! Remember, converting bytes to a string requires attention to special characters, and our more robust solution above should help.